
Instruction Interpreter
|
4
Instruction Interpreter |
This chapter describes the operation of the Mesa instruction interpreter. Only the main loop is contained here; the individual instructions are covered in other chapters. The instruction formats, instruction fetch, effective address calculation, and opcode dispatch are defined in this chapter. A description of exception processing (traps, faults, and interrupts) is also included. In the last section, the initial state of the processor is defined.
After initialization, the processor repeatedly interprets instructions as coded in the Processor routine. This task includes checking for pending interrupts and possible timeouts before the execution of each instruction.
Abort: ERROR = CODE;
Processor: PROCEDURE =
BEGIN
Initialize[];
DO ENABLE Abort => LOOP;
interrupt: BOOLEAN  CheckForlnterrupts[];
timeout: BOOLEAN CheckForTimeouts[];
IF interrupt OR timeout THEN Reschedule[preemption: TRUE]
ELSE IF running THEN Execute[];
ENDLOOP;
END;
CheckForlnterrupts[];
timeout: BOOLEAN CheckForTimeouts[];
IF interrupt OR timeout THEN Reschedule[preemption: TRUE]
ELSE IF running THEN Execute[];
ENDLOOP;
END;
The initial state of the processor and its memories is defined in §4.7. The checks for pending interrupts and timeouts are discussed briefly in §4.6.2 and more thoroughly in §10.4. Reschedule and running are also defined there. The Execute routine defines instruction fetch, instruction decode, and opcode dispatch. (Details are in §4.3 and §4.5.)
In the event of an exception, the trap and fault routines use the signal Abort to return control to the main loop. In this situation, the processor continues executing instructions using the machine state established by the trap or fault routine; the intermediate state of the current opcode routine (and any routines that it has called) is discarded as a result of catching the signal. Abort is the only signal defined in the code. It is raised only by the trap and fault routines (see §4.6.1), and it is unwound only by the Processor routine.
The Mesa instruction set is composed of variable-length instructions of one, two, or three bytes in length. The most frequently used operations are encoded in a single byte. The first byte is always part of the opcode, and since there are more than 256 instructions, some extended opcodes occupy two or more bytes (the assignment of opcode values is given in the Appendix). In addition to the opcode, an instruction can contain one or two operand bytes, called <4.2>alpha and <4.2>beta. Additional operands may be present on the evaluation stack. The following illustration shows the possible instruction formats:
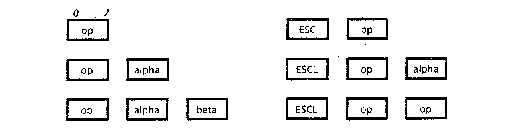
Design Note: The maximum size of an instruction is three bytes. Therefore, extended opcodes of two (or three) bytes can have only one (zero) operand bytes. This restriction establishes a minimum size for the optional instruction buffer (see §4.3).
Design Note: There are two escape opcodes, one for two-byte instructions (ESC) and one for three-byte instructions (ESCL). In both cases, the second byte is an extended opcode. This feature enables the programmer to determine instruction lengths by examining only the first instruction byte.
Design Note: The opcode values zero and 255 are reserved for internal use by the processor implementation. The programmer must ensure that these values will never appear as opcodes in an instruction stream contained in a code segment.
Opcode and operand bytes are fetched from the code segment by the GetCodeByte routine. It maintains the program counter PC by incrementing it each time a byte is fetched. Thus the PC always points just beyond the current instruction byte (unless it is explicitly modified by the instruction, as in a jump). The beginning of the current instruction is pointed to by the variable savedPC, defined with Execute below (§4.5).
GetCodeByte: PROCEDURE RETURNS [UNSPECIFIED[0..377B)] =
BEGIN
even: BOOLEAN = (PC MOD 2) = 0;
word: BytePair = ReadCode[];
PC PC + 1;
RETURN[IF even THEN word.left ELSE word.right];
END;
All operations on the PC are performed modulo 216, ignoring overflow. Backward jumps are performed by adding large unsigned positive numbers to the PC; this is equivalent to adding signed, two's-complement negative numbers, since overflow is ignored.
The following routine is used to fetch a word from the code segment; note that the bytes that make up the word may cross a word boundary in the instruction stream.
GetCodeWord: PROCEDURE RETURNS [UNSPECIFIED] =
BEGIN
word: BytePair;
word.left GetCodeByte[];
word.right GetCodeByte[];
RETURN[word];
END;
Implementation Note: As written, the GetCodeByte routine fetches a full word from memory each time it is called. To avoid these extra memory references, and generally to speed execution, most models of the processor implement an instruction buffer which holds the next few bytes of the code stream. Take care to ensure that page faults do not occur until the word containing the requested byte would have been accessed by calls on the above routines.
There are no fixed address fields or addressing modes defined by the instruction format, since the address computation performed by an instruction is determined entirely by its opcode. However, there are some common patterns shared by several instructions. In general, addresses are computed in one of the following ways:
If the operands are on the evaluation stack, the stack pointer is used to address them (§3.3.2, §5).
If the operands are in the current local or global frame, the registers LF and GF are combined with an offset taken from the stack, the opcode, or the operand bytes alpha and beta (§7.2).
Operands elsewhere in memory are referenced using pointers taken from the stack or from the local or global frame. These pointers are usually combined with offsets obtained from the stack, the opcode, or the operand bytes alpha and beta §7.3.5).
Operands located in the code are referenced using an offset from the code base CB or the PC. These offsets are taken from the stack, the opcode, or the operand bytes alpha and beta (§6, §7.5.1, and §1).
Programming Note: The architecture includes provisions for mapping code segments out of virtual as well as real memory (§9.5.1). Absolute virtual pointers into the code segment should therefore be used with caution. The processor never uses such pointers (except for CB), and all references to the code are relative to the code base. Furthermore, interruptible instructions (§4.6.2) must not save the code base as part of their intermediate state.
A complete definition of address calculation appears in the description of each instruction contained in the chapters that follow.
The following routine defines the initial processing of each opcode. Subsequent actions appear in separate routines defined for each instruction (or instruction class). If an opcode other than ESC or ESCL is unimplemented, an OpcodeTrap is generated (§9.5). Unimplemented ESC or ESCL opcodes generate an EscOpcodeTrap (§9.5). Identifiers beginning with z represent values of single byte opcodes, identifiers beginning with a represent values of ESC opcodes, and identifiers beginning with b represent values of ESCL opcodes. These conventions are fully listed in Appendix A.
break: BYTE;
savedPC:CARDINAL;
savedSP: StackPointer;
Execute: PROCEDURE =
BEGIN
savedPC PC; savedSP SP;
Dispatch[GetCodeByte[]];
END;
Dispatch: PROCEDURE [opcode: BYTE] =
BEGIN
SELECT opcode FROM
zLL0 => LLn[O];
ZLLl => LLn[l];
. . .
zLLB => LLB[];
. . .
zBRK => BRK[];
zESC =>
SELECT opcode GetCodeByte[] FROM
aMW => MW[];
aMR =>
MR[];
. . .
. . .
ENDCASE => EscOpcodeTrap[opcode];
zESCL => SELECT opcode GetCodeByte[] FROM
bROB => ROB[];
. . .
ENDCASE => EscOpcodeTrap[opcode];
ENDCASE => OpcodeTrap[opcode];
END;
Execute begins by saving the current values of the program counter and stack pointer before each instruction is executed (and before its opcode is fetched). This method allows the trap and fault routines to restore these variables to their original values so that the aborted instruction can be restarted (see below). Most jump instructions also use savedPC as the base for relative addressing (§6). The break byte and Dispatch are used by the breakpoint mechanism (§9.5.4).
An exception occurs when the processor determines that execution of the current instruction should be halted (perhaps before it has even begun), and that some other context or process should be run. There are three types of exceptions: traps, faults, and interrupts.
An instruction experiences a fault if it causes a page fault (§3.1.11, a write protect fault §3.1.11, or a frame allocation fault (§9.2). A fault calls a fault routine, which causes a process switch. This changes not only the current context, including the evaluation stack, but also the MDS and PSB registers as well, and makes a software fault handler ready, if it is not currently ready. (A trap handler, on the other hand, runs in the same process, and uses the same Main Data Space, as the context that caused the trap.) Details of the process switching mechanism and the fault routines are contained in §10.4.
Exceptions can occur at any time during the execution of an instruction. Therefore, care must be taken to define the state of the context when an exception occurs. This precaution allows. the programmer to correct the cause of the problem (if possible) and restart the instruction that trapped, faulted, or was interrupted. Stated more precisely: if an exception occurs, the processor state, including the current context, the evaluation stack, and the other registers (defined in §3.3) must be restored to a state which, when used to restart the context, can result in the completion of the instruction as though the exception had not occurred. This is call the restart rule, and like all good rules, there are exceptions involving fatal errors from which processing can not be resumed. They are discussed below.
The restart rule is intended to allow trap and fault handlers themselves to experience traps and faults. No matter how deeply nested the processor becomes in exception routines, only the last exception handler actually will get control. This handler will see the state of a context or a process that was not the original state or context. It only sees the state or context (which was excepted) of which it got control. When the trap or fault handler completes exception processing, it restarts the context in which its exception occurred. Occasionally the restart causes another trap or fault; it can even cause the same trap again.
The restart rule applies under a wide range of conditions. One extreme includes recoverable FAULTs, such as page faults, where the entire processor state from the beginning of the opcode is restored. For some cases of faults, the restart rule is used to restore only a partial state of the processor. At the other extreme are fatal traps. The processor is responsible only for leaving as much information as possible for debugging purposes. The following paragraphs cover these instances in more detail.
Generally, the processor adheres to the restart rule by restoring itself to what its state had been at the beginning of the current instruction Because Execute saves the initial values of the stack pointer and program counter, the opcode routines are free to remove operands from the stack and fetch operand bytes, knowing that the trap and fault routines (§9.5.2, §10.4.3) will restore the SP and PC in the event of an exception (interrupts are handled differently; §4.6.2). The opcodes do not, however, push results back onto the stack. That method would destroy the original operands! They must be preserved until all possibility of a trap or fault has passed. Instead, the opcode routines use temporary variables to hold intermediate results until exceptions are no longer possible (for example, see RDO, RDB, RDLO, and RDLB in §7.3.1.1 and XFER in §9.3).
Another approach to recovering from a fault is to save and restore the processor state at any point where a fault may occur. This restores only that part of the state that had been altered. Because of its complexity, this approach is used only for lengthy opcodes such as those that transfer large blocks of data (see below).
Certain changes in the state of the computation are allowed even if a subsequent trap or fault could occur. In particular, any operation that is idempotent, and therefore by definition can be performed any number of times with the same result, can be completed before a subsequent operation that may cause a trap or fault. Likewise, instructions that update multiword structures in memory are not required to do so atomically. The restart rule can be interpreted to mean that the entire instruction is re-executed, without considering the effects of other processes that may have executed between the time of the exception and the resumption of the instruction For example, instructions that store LONG types are not required to update the double word atomically. They can store the first word, and if a fault occurs on the second word, establish a state that will cause both words to be stored (the first for a second time) when the instruction is restarted; the modified locations need not be restored to their original values when the fault occurs (see SLD0, SLDB, WDBL in §7).
Programming Note: Multiword structures that must be updated atomically with respect to page faults should not be allocated across a page boundary. If a data structure requires synchronized access by several processes, the locking mechanism provided by monitors (§10) can be used.
For instructions that operate on large multiword structures, efficiency considerations discourage the strict interpretation of the restart rule. Strict interpretation would imply that the entire operation be started over. The BLT instruction (§8), which copies a block of up to 64K words from a source to a destination address, is an example. Each time around its main loop, it modifies the processor state so that the word transferred is no longer specified by the instruction operands. If an exception occurs during the next iteration, resumption results in transfer of the remaining words, without disturbing the data previously moved. All of the block-transfer instructions use this algorithm. Because of potentially long execution times, they also check for interrupts in their main loops.
Finally, there is an exception to the restart rule: some traps are considered fatal, so a context that experiences these traps can never be resumed (correctly). The state of the context is therefore undefined. Fatal traps have names that end with "Error" (e.g., StackError, RescheduleError). Depending on the type of error, either the current context, the current process, or the entire system may be unresumable (see §9.5).
Implementation Note: Although the state of a context that experiences a fatal trap is undefined, the processor should make an attempt to establish a context that is meaningful to the programmer for debugging purposes. Ideally, the program counter should point to the offending instruction, and the stack and stack pointer should reflect its operands. At a minimum, the value of the local frame pointer LF should be available, since little debugging is possible without it.
An interrupt occurs in response to a request for service, called a wakeup, from an external device or controller. Its effect is to notify a condition variable, which may make a software interrupt handler ready (if one is waiting). This may in turn cause a process switch (depending on the handler's priority; see §10.4).
As mentioned above, interrupts are handled differently with respect to the restart rule. Wakeups are buffered in the status register WP (wakeups pending), but otherwise ignored by most instructions (except the block transfers). If the main loop of the Processor routine detects a non-zero value in this register, execution of the current instruction is not started, and a possible process switch occurs, the details of which are described in §10.4. Because the check for interrupts is made before instruction execution begins (in fact, before the opcode is fetched), most instructions are not concerned with the possibility of an interrupt. However, the block transfer instructions (§8) are implemented in a fashion that allows their execution to be suspended and later resumed, as explained above.
The routine below defines the initial conditions when the processor first starts execution; it sets up the processor registers and the current context. Initialize presumes that the memory map has been set to reflect all of the available real memory. Each real memory page must be entered in exactly one map entry corresponding to some existing virtual page, but not all mapped virtual memory need be contiguous. The protected flag of these map entries must be FALSE, but the dirty and referenced flags may be in an undefined state. The flags of all other map entries not assigned to real pages must be vacant (see §3.1.1). The reserved locations in the BootArea and the IOArea must be mapped.
Design Note: Not all of the real memory attached to the machine needs to be made available to the processor at initialization. In particular, so called buffered devices that require dedicated real memory will normally make this memory known to the software through the device implementation.
Initialization turns off interrupts, clears the process timeout registers, clears the XFER trap status register, and sets the running flag (§10). It empties the stack, initializes the MDS to the first 64K, and clears the break byte (§9.4.5). Initialize then performs an XFER through a fixed location in the System Data table. (sBoot is defined in Appendix A.)
Initialize: PROCEDURE =
BEGIN
-- Process registers
WP 0;
WDC 1;
XTS 0;
time IT;
running TRUE;
-- Context initialization
SP 0;
break 0;
PSB 0;
MDS LOOPHOLE[LONG[O]];
XFER[dst: @SD[sBoot], src: 0, type: call];
END;
Note that a trap or fault during the initial XFER results in an undefined machine state. (The call from the main program to Initialize is outside the scope of the Abort catch phrase.)
Programming Note: Except for the execution of the XFER (whose destination is an indirect control link), initialization does not reference main memory or disturb its contents. Previous [TOC] Next
[last edited 4/10/99 12:03AM]